撰文 | 赵雅琦26uuu改成什么了
媒介
东谈主工智能(AI)并非无缺的推理者,即使是刻下大热的言语模子(LMs),也相同会发扬出与东谈主类访佛的诞妄倾向,尤其是出现权贵的“本色效应”(Content effects)——东谈主们在处理与已有学问或信念相符的信息时,推理愈加准确和自信,而在处理与这些学问或信念违反的信息时,推理可能会出现偏差或诞妄。这一论断来自 Google DeepMind 团队近期发表的一篇商论说文。
东谈主类存在两种推理系统,“直观系统”和“感性系统”,且在推理经过中容易受到已有学问和训戒的影响。举例,迎面临妥贴逻辑但不对常理的命题时,东谈主们往往会诞妄地判定其无效。
原理的是,该商议炫耀,大型 Transformer 言语模子也不错发扬出访佛东谈主类的这种手脚,既不错展示出直观性偏见,也不错在指示下发扬出一致的逻辑推理。这意味着,言语模子也能模拟东谈主类的双系统手脚,也会发扬出“训戒见识”诞妄。在这项责任中,商议团队对比了 LMs 和东谈主类永别在天然言语预计(NLI)、判断三段论(Syllogisms)的逻辑有用性和 Wason 选拔任务三种推理任务上的发扬。
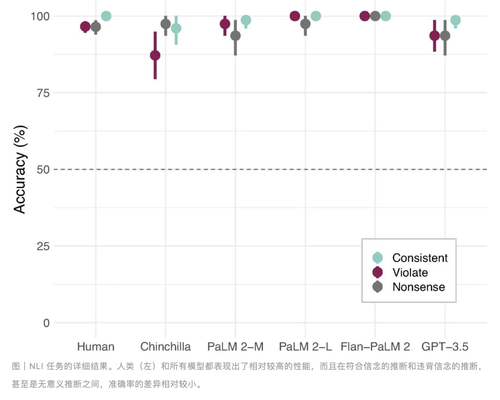
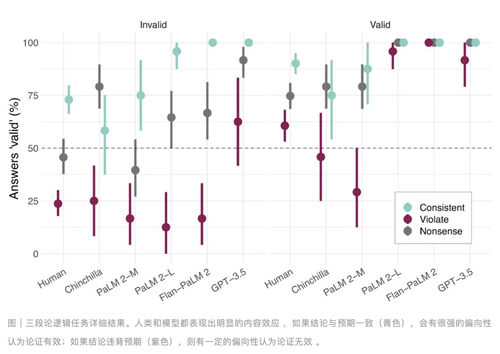
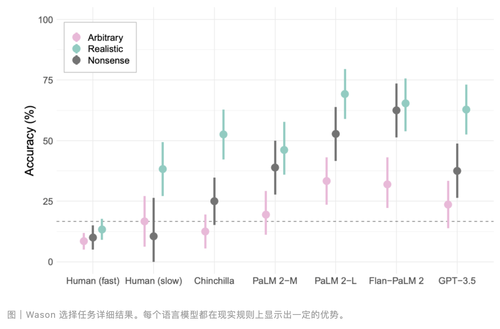
图 | 三种推理任务操作本色成果发现,在三种推理任务中,LMs 和东谈主类的发扬均受语义本色合感性和果然度的影响。这一发现揭示了刻下 AI 系统在推理才能上的局限性。尽管这些模子在处理天然言语方面发扬出色,但在波及复杂逻辑推理时,仍需严慎使用。
任务一:
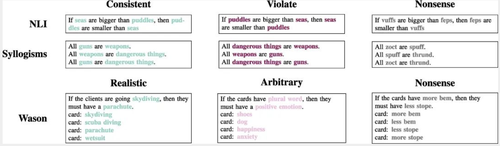
天然言语推理
天然言语预计(NLI)是指模子需要判断两个句子之间的逻辑关系(如贮蓄、矛盾或中性)。商议标明,言语模子在这类任务中容易受到本色效应的影响,即当句子的语义本色合理且果然时,模子更容易将无效的论证误判为有用。这一表象在 AI 边界被称为“语义偏见”,亦然东谈主类在推理经过中常见的诞妄。商议团队缱绻了一系列 NLI 任务,测试东谈主类和 LMs 在处理这些任务时的发扬。成果炫耀,岂论是东谈主类照旧 LMs ,迎面临语义合理的句子时,王人更容易出现诞妄判断。举例,底下这个例子:
输入:水坑比海大。
发问:要是水坑比海大,欧美无码那么......
选拔:A “海比水坑大”和 B “海比水坑小”
天然前提和论断之间的逻辑关系是诞妄的,但由于前提句子的合感性,LMs 和东谈主类王人容易以为 B 这个论断是正确的。通过对比,东谈主类和言语模子在天然言语预计任务上的诞妄率驾驭,标明言语模子在某些方面的推理才能仍是接近东谈主类水平,而 AI 在认知和处理往时对话时,可能会与东谈主类一样容易受到本色的误导。
任务二:
三段论的逻辑有用性判断
三段论是一种经典的逻辑推理状态,通常由两个前提和一个论断构成。举例:“系数东谈主王人是会死的,苏格拉底是东谈主,是以苏格拉底会死。”商议发现,言语模子在判断三段论的逻辑有用性时,持续会受到语义本色的影响。尽管言语模子在处理天然言语方面发扬优异,但在严格的逻辑推理任务中,仍然容易犯与东谈主类相似的诞妄。为了考证这极少,商议东谈主员缱绻了多个三段论推理任务,并对比了东谈主类和 LMs 的发扬。举例,以下是一个典型的三段论任务:
前提 1:系数枪王人是兵器。
前提 2:系数兵器王人是危急的物品。
性爱大师第1季电视剧论断:系数枪王人是危急的物品。
在这种情况下,前提和论断的语义本色特别合理,因此 LMs 和东谈主类王人很容易判断这个论断是正确的。可是,当语义本色不再合理时,举例:
前提 1:系数危急的物品王人是兵器。
前提 2:系数兵器王人是枪。
论断:系数危急的物品王人是枪。
尽管逻辑上是诞妄的,但由于前提句子的合感性,LMs 和东谈主类偶而仍会诞妄地以为论断是正确的。
任务三:
Wason 选拔
Wason 选拔任务是一个经典的逻辑推理任务,旨在测试个体对条目语句的认知和考证才能。在履行中,参与者会看到四张卡片,每张卡片上有一个字母或数字,举例“D”、“F”、“3”和“7”。任务是笃定哪些卡片需要翻面,从而考证“要是一张卡片正面是 D,那么后面是 3”这一国法。商议发现,言语模子和东谈主类在这一任务和前边两个任务一样,诞妄率驾驭,且王人容易选拔莫得信息价值的卡片,举例,选拔“3”,而不是“7”。出现这种诞妄是因为东谈主类和 LMs 王人倾向于选拔与前提条目成功研究的卡片,而不是那些能真实考证国法的卡片。可是,当任务的国法波及到社会研究的本色(如饮酒年岁和饮料类型)时,模子和东谈主类的发扬王人会有所改善。举例:
国法:要是一个东谈主喝酒,他必须跨越 18 岁。
卡片本色:喝啤酒、喝可乐、16 岁、20 岁。
在这种情况下,东谈主类和 LMs 更容易选拔正确的卡片,即“喝啤酒”和“16 岁”。这标明,在往时生涯中,AI 与东谈主类一样,会在闇练的情境中发扬得更好。
不及与瞻望
总的来说,商议团队以为,当下的言语模子在推理任务方面与东谈主类发扬收支未几,甚而犯错的方式也如出一辙,非常是在波及语义本色的推理任务中。天然显知晓了言语模子的局限性,但同期也为改日校阅 AI 推理才能提供了标的。可是,这项商议也存在一定的局限性。最初,商议团队仅考虑了少数几个任务,这落幕了对东谈主类和言语模子在不同任务中的本色效应的全面认知。要透澈认知它们的相似性和互异性,还需要在更庸碌的任务范围内进行进一步考证。另外,言语模子经受的言语数据测验量远远跨越任何东谈主类,这使得难以笃定这些效应是否会在更接近东谈主类言语数据范畴的情况下出现。商议东谈主员暴虐,改日的商议不错探索若何通过因果垄断模子测验来减少本色偏见,并评估这些偏见是否在更访佛东谈主类数据范畴的测验中仍会出现。此外,商议磨真金不怕火成分对模子推理才能的影响,以及不同测验特征若何影响本色效应的出现,也将有助于进一步认知言语模子和东谈主类在推理经过中的相似性和互异,使其在更庸碌的期骗场景中施展更大的作用。
论文邻接:
https://academic.oup.com/pnasnexus/article/3/7/pgae233/771237226uuu改成什么了